
The Dependency Inversion Principle (DIP) is one of the five essential SOLID design principles in C# and .NET. These principles are guidelines for the proper usage of object-oriented features. The DIP definition is:
a. High-level modules should not depend on low-level modules. Both should depend on abstractions.
b. Abstractions should not depend on details (concrete implementation). Details should depend on abstractions.
In plain words, the Dependency Inversion Principle in C# tells us to depend on abstractions (interfaces) rather than on concrete classes. The high-level code that holds the business logic and the low-level code that holds the implementation details should both rely on the same interface, so that neither one is welded to the other. This single rule is what keeps a .NET codebase loosely coupled, testable and open to change.
The DIP was introduced in the 90s by Robert C Martin. Here is the original article.
SOLID Principles Summary

Before delving into the Dependency Inversion Principle, let’s take a quick look at how it stands in the SOLID design principles:
- The Single Responsibility Principle (SRP): A class should have one reason to change. This principle is about how to partition your logic into classes and avoid ending up with some monster classes (known as god class).
- The Open-Close Principle (OCP): Modules should be open for extension and closed for modification. To implement a new feature, it is better to add a new derived class instead of having to modify some existing code.
- The Liskov Substitution Principle (LSP): Methods that use references to base classes must be able to use objects of derived classes without knowing it. Array implements IList<T> but throws NotSupportException on IList<T>.Add(). This is a clear LSP violation.
- The Interface Segregation Principle (ISP): The client should not depend by design on methods it does not use. This is why interfaces like IReadOnlyCollection<T> have been introduced. Often the client just needs a subset of features like read-only access instead of full read-write access.
- The Dependency Inversion Principle (DIP): Depend on abstractions, not on implementations. Interfaces are much less subject to changes than classes, especially the ones that abide by the (ISP) and the (LSP).
The Dependency Inversion Principle Explained
The goal: an architecture resilient to changes
As for each SOLID principle, DIP is about system maintainability and reusability. Inevitably some parts of the system will evolve and will be modified. We want a design that is resilient to changes. To avoid that a change breaking too much, we must:
- First, identify parts of the code that are change-prone.
- Second, avoid dependencies toward those change-prone code modules.
High-level modules versus low-level modules
The DIP definition revolves around two notions worth clarifying before we go further. A high-level module holds the policy: the business rules and the orchestration logic that give the application its value. A low-level module deals with the details: reading a file, opening a database connection, sending bytes over the network. Intuitively we let the high-level code call the low-level code directly, and this is precisely the dependency the DIP asks us to break.
The reason is a matter of value and stability. The high-level policy is what we care about the most, yet in a naive design it ends up depending on volatile low-level details. When a detail changes, say a new database engine or a new transport protocol, the precious high-level code gets impacted. By making both depend on an abstraction instead, the dependency arrow that used to point from high-level code to low-level code is removed. The policy no longer knows, nor cares, which concrete detail serves it at runtime.
Interfaces are stable
The Liskov Substitution Principle (LSP) and the Interface Segregation Principle (ISP) articles explain that interfaces must be carefully thought out. Both principles are the two faces of the same coin:
- ISP is the client perspective: If an interface is too fat probably the client sees some behaviors it doesn’t care for.
- LSP is the implementer perspective: If an interface is too fat probably a class that implements it won’t implement all its behaviors. Some behavior will end up throwing something like a NotSupportedException.
Efforts put in applying ISP and LSP result in interface stability. As a consequence, these well-designed interfaces are less subject to changes than concrete classes that implement them.
Also having stable interfaces results in improved reusability. We are pretty confident that the interface IDisposable will never change. Our classes can safely implement it and this interface is re-used all over the world.
First C# Example of the Dependency Inversion Principle
In this context, the DIP states that depending on stable interfaces is less risky than depending on change-prone implementations. DIP is about transforming this code:
|
1 2 3 |
static void ClientCode(SqlConnection sqlConnection) { sqlConnection.Open(); } |
into this code:
|
1 2 3 |
static void ClientCode(IDbConnection dbConnection) { dbConnection.Open(); } |
DIP is about removing dependencies from high-level code (like the ClientCode() method) to low-level code, low-level code being implementation details like the SqlConnection class. For that, we create interfaces like IDbConnection. Then both high-level code and low-level code depend on these interfaces. The key is that SqlConnection is not visible anymore from the ClientCode(). This way the client code won’t be impacted by implementation changes, like when replacing the SQL Server RDBMS implementation with MySql for example.
C# Example of the Dependency Inversion Principle
Now let’s illustrate the DIP with a real C# example. Here is usual C# code where a class Switch is used to operate a Lamp:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
Lamp lamp = new Lamp(State.Off); Switch lightSwitch = new Switch(lamp); lightSwitch.Press(); enum State { On, Off } class Lamp(State State) { public void Operate() { State = State == State.On ? State.Off : State.On; Console.WriteLine("Lamp is switched " + (State == State.On ? "On" : "Off")); } } class Switch { private Lamp lamp; public Switch(Lamp device) { this.lamp = device; } public void Press() { lamp.Operate(); } } |
The main issue with this code is that the high-level class Switch is bound with the class Lamp. There are two disadvantages to that:
- Switch cannot be used with something else than a Lamp. In the real world, a switch can work with any kind of electric device, an AirConditioner, a GarageDoor or a Television.
- The class Lamp is an implementation. An implementation can change, it can go from 220 volts to 110 volts for example. When the class Lamp changes, it can break the class Switch.
Introducing Abstraction
By introducing an IDevice interface, both design issues are solved:
- The class Switch can work with anything implementing the interface IDevice like an AirConditioner for example.
- Internal details of the class Lamp can change. As long as a Lamp is an IDevice, the class Switch won’t be broken.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
IDevice lamp = new Lamp(State.Off); Switch lightSwitch = new Switch(lamp); lightSwitch.Press(); interface IDevice { void Operate(); } enum State { On, Off } class Lamp(State State) : IDevice { public void Operate() { State = State == State.On ? State.Off : State.On; Console.WriteLine("Lamp is switched " + (State == State.On ? "On" : "Off")); } } class AirConditioner(State State) : IDevice { public void Operate() { State = State == State.On ? State.Off : State.On; Console.WriteLine("AirConditioner is switched " + (State == State.On ? "On" : "Off")); } } class Switch { private IDevice device; public Switch(IDevice device) { this.device = device; } public void Press() { device.Operate(); } } |
Notice that the dependency has been turned around. Before, Switch pointed to the concrete Lamp. Now Lamp and AirConditioner point up to the IDevice abstraction, and so does Switch. The high-level class stopped depending on the low-level classes. That reversal is exactly what the word Inversion stands for in the principle’s name.
Benefits of applying the Dependency Inversion Principle
In the refactored code in the previous section we can see that:
- Code is Loosely-Coupled: Only the main method knows about what is switched on or off. Devices and Switches don’t know about each other.
- Code is Resilient to Changes: The main method, the class Switch, Lamp and AirConditioner, all depend on the interface IDevice. Hopefully, this interface is stable. It has the single responsibility of making a device operatable.
- Code is Testable: Because Switch only sees IDevice, a unit test can hand it a fake device and assert how it behaves, with no real Lamp involved.
As a side note, the class Lamp is an implementation details of an IDevice. Implementation details depend on the interface, not the opposite. Here is the meaning of the word Inversion in the DIP principle.
Making the Dependency Inversion Principle Actionable with the Level metric
Several code metrics can be used to measure, and thus constraint, the usage of DIP. One of these metrics is the Level metric. The Level metric is defined as follows:

From this diagram we can infer that:
- The Level metric is not defined for components involved in a dependency cycle. As a consequence, null values can help track component dependency cycles.
- The Level metric is defined for any dependency graph. Thus a Level metric can be defined for various granularity: methods, types, namespaces and projects.
DIP mostly states that types with Level 0 must be interfaces and enumerations. If we say that a component is a group of types (like a namespace or a project) the DIP states that components with Level 0 must contain mostly interfaces and enumerations. With a quick code query like this one you can have a glance at types Level and check if most of low level types are interfaces:
|
1 2 3 4 |
from t in JustMyCode.Types where t.Level != null orderby t.Level ascending select new { t, t.Level } |

The Level metric can be used to track classes with a high-value for the Level metric. This is an indication that some interfaces must be introduced to break the long chain of concrete code calls:
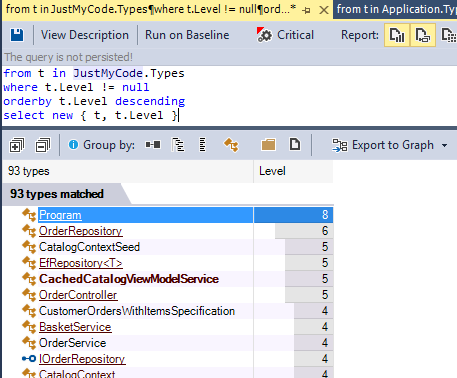
The class Program has a Level of 8. If we look at the dependency graphs of types used from Program we can certainly see opportunities to introduce abstractions to be more DIP compliant:

DIP versus Dependency Injection (DI)
The acronym DI is used for Dependency Injection. Since it is almost the same as the DIP acronym this leads to confusion. The I is used for Inversion or Injection which might add to confusion. Hopefully DI and DIP are very much related.
- DIP states that classes that implement interfaces are not visible to the client code.
- DI is about binding classes behind the interfaces consumed by client code.
DI means that some code, external to client code, configures which classes are used at runtime by the client code. This is simple DI:
|
1 2 3 4 5 6 7 |
static void DICode() { IDbConnection dbConnection = new SqlConnection(); ClientCode(dbConnection); } static void ClientCode(IDbConnection dbConnection) { // Client code has no idea what's behind IDbConnection dbConnection.Open(); } |
Many .NET DI frameworks exist to offer flexibility in binding classes behind interfaces. Those frameworks are based on reflection and thus, they offer some kind of magic. The syntax looks like:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
// Autofac DI var builder = new ContainerBuilder(); builder.RegisterInstance(new SqlConnection()).As<IDbConnection>(); // UnityContainer DI IUnityContainer container = new UnityContainer(); container.RegisterType<IDbConnection, SqlConnection>(); // NInject DI public class Bindings : NinjectModule { public override void Load() { Bind<IDbConnection>().To<SqlConnection>(); } } |
Since .NET Core, the framework even ships with its own container, Microsoft.Extensions.DependencyInjection, so most ASP.NET Core and modern .NET applications now register their services right in Program.cs without pulling a third-party library.
And then comes the Service Locator pattern. The client can use the locator to create instances of the concrete type without knowing it. It is like invoking a constructor on an interface:
|
1 |
IDbConnection dbConnection = Locator.Resolve<IDbConnection>(); |
Thus while DIP is about maintainable and reusable design, DI is about flexible design. Both are very much related. Let’s notice that the flexibility obtained from DI is especially useful for testing purposes. Being DIP compliant improves the testability of the code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
class MockConnection : IDbConnection { void Open() { ... } ... } [Test] public void MyTest() { IDbConnection dbConnection = new MockConnection(); // Abstract the test from the database layer var result = ClientCode(dbConnection); Assert.ThingsOn(result); } static Result ClientCode(IDbConnection dbConnection) { dbConnection.Open(); // ... do interesting stuff return result; } |
The short way to remember it: DIP is the principle that says depend on an abstraction, while Dependency Injection is one concrete technique that supplies the implementation behind that abstraction. You can respect DIP without any DI framework, and you reach for DI precisely because your code already follows DIP.
DIP versus Inversion of Control (IoC)
The Inversion word is used both in DIP and IoC acronyms. Here also this provokes confusion. Keep in mind that the word Inversion in the DIP acronym is about implementation details depending on interfaces, not the opposite. The Inversion word in the IoC acronym is about callback from Framework.
IoC is what differentiates a Framework from a Library. A library is typically a collection of functions and classes. On the other hand, a framework also offers reusable classes but also relies on callbacks. For example, UI frameworks offer many callback points through graphical events:
|
1 2 3 4 5 6 7 |
class MyForm : FrameworkForm { private Button m_Button = new Button(); public MyForm() { m_Button.OnClick += m_ButtonOnClick; } private void m_ButtonOnClick(Sender sender) { ... } } |
The method m_ButtonOnClick() is bound to the Button.OnClick event. It is a callback method. Instead of client code calling a framework method, the framework is responsible for calling back client code. This is an inversion in the control flow.
We can see that IoC is not directly related to DIP. However, both principles rely on abstractions to inverse the direction of a dependency.
- DIP uses abstraction to achieve a loosely-coupled design.
- IoC uses abstraction as a means to call back.
Because these three terms get mixed up so often, here is a side-by-side summary:
| Term | What it is | What it gives you |
|---|---|---|
| DIP – Dependency Inversion Principle | A design principle: depend on abstractions, never on concrete implementations. | Maintainable and reusable design. |
| DI – Dependency Injection | A technique: an outside party supplies the concrete instance behind an interface. | Flexible, easily testable design. |
| IoC – Inversion of Control | A design style: the framework calls your code back instead of the other way around. | Extensibility through callbacks. |
Common mistakes when applying the Dependency Inversion Principle
DIP is easy to misread, and over the years we have seen the same traps over and over:
- Wrapping every single class behind an interface. An interface that has exactly one implementation and will never have another adds indirection without adding value. Abstract the dependencies that are genuinely change-prone or that you need to fake in tests, not all of them.
- Putting the interface next to its implementation. When IRepository lives in the same low-level assembly as SqlRepository, the high-level code that references the interface still drags the low-level project along. The abstraction should belong with, or above, the high-level code that owns it.
- Confusing DIP with simply using a DI container. Registering a concrete class as itself in a container is not DIP. You only invert the dependency when the client depends on the abstraction.
- Leaking implementation details through the interface. An IDbConnection that exposes SQL-Server-specific options is no longer a real abstraction. Keep interfaces honest, in the spirit of the ISP and LSP.
Frequently Asked Questions about the Dependency Inversion Principle
What is the Dependency Inversion Principle in C#?
The Dependency Inversion Principle is the “D” in SOLID. It states that high-level modules and low-level modules should both depend on abstractions (interfaces or abstract classes) rather than the high-level code depending directly on concrete low-level classes. In C# this usually means a class accepts an interface through its constructor instead of instantiating a concrete type itself.
What is the difference between Dependency Inversion and Dependency Injection?
Dependency Inversion is a design principle, Dependency Injection is a technique that helps you apply it. DIP tells you to depend on an abstraction; DI is the act of passing the concrete implementation of that abstraction into the client from the outside. You can follow DIP with plain constructor parameters and no DI container at all.
Why is it called “inversion”?
In a conventional design the high-level code depends on the low-level code, so the dependency points downward. DIP reverses, or inverts, that arrow: the low-level implementation now depends on an abstraction defined for the high-level code. The detail points up to the interface, not the other way around.
Is the Dependency Inversion Principle the same as Inversion of Control?
No. DIP is about which direction your dependencies point (toward abstractions). Inversion of Control is about who is in charge of the control flow, typically a framework calling your code back through events or callbacks. They both rely on abstractions, but they answer different questions.
When should I not apply the Dependency Inversion Principle?
When the dependency is stable and will never need to be swapped, faked or extended, an extra interface is just noise. The KISS principle wins: do not invert a dependency that gives you nothing in return.
How do I measure how well my code follows DIP?
Static analysis helps. With NDepend, the Level metric flags concrete types sitting low in the dependency graph and surfaces dependency cycles, both of which point to places where introducing an abstraction would make the code more DIP compliant.
Conclusion
As with other SOLID principles, the Dependency Inversion Principle is a key principle to wisely use the OOP abstraction and polymorphism concepts. This results in improving code maintainability, reusability and testability of your code.
This article concludes this SOLID posts series. Being aware of SOLID principles is not enough. When making design decisions one should take account of SOLID. But their usage must be constrained by the KISS principle: Keep It Simple Stupid. As explained in the post Are SOLID Principles Cargo Cult? it is easy to write spaghetti code in the name of SOLID principles. Then one can learn from experience. With years, identifying the right abstractions and partitioning properly the business needs in well-balanced classes is becoming natural.