The source code is the design. This famous motto means that no matter how many diagrams you draw and discuss with your colleagues, the important point is how the existing source code is actually structured.
The need for visualizing code
First, let’s distinguish between the static view of code (how classes depend on each other in source code) and the dynamic view of code (how objects depend on each other at runtime).
Designing clean architecture is related to the static view of code. Clean architecture leads to high maintainability, less error-prone code and overall it keeps developers both productive and motivated. On the other hand caring for the dynamic view is useful for performance and memory management purposes. In this post we’ll focus on the static view.
Any sufficiently large enough system cannot be mastered without some sort of visualization. Consequences of the lack of control on the code structure are entangled components, code smells and architecture erosion. The code base ends up being a mess (spaghetti code metaphor) and the cost of maintenance becomes prohibitive. Unfortunately this scenario is more the rule than the exception in the software industry.
I always had a passion for visualizing existing code and clean architecture. This is not surprising that I created the tool NDepend 15 years ago that now proposes several software architecture diagrams. In this post I will describe our code visualization choices.
Architecture, Dependencies and OOP
Software architecture relates to dependencies between the various elements of a code base: components, packages, namespaces, classes, methods, fields… All Object-Oriented Programming (OOP) concepts are somehow related to dependencies:
- Encapsulation: Let decide which element the outside world can depend on and which element must be kept private within an implementation.
- Abstraction: Avoid being dependent on implementation details that typically change more often than carefully thought-out abstraction.
- Polymorphism: Avoid being dependent on implementation that is chosen at runtime, based on various criteria: type of the target object, generic type parameter (parametric polymorphism) or even type of the object passed as parameter (double dispatching in the visitor pattern)
- Inheritance: It is not only a powerful way of reusing code, but it also lets the client code decides which level of specialization it should depend on, the lower the better. Depending on a base class or an interface means that the code can operate on a wider range of objects. For example relying on IEnumerable<T> only, means that the code can work with any collection of T (array, list, hashset…).
Dependency Graph
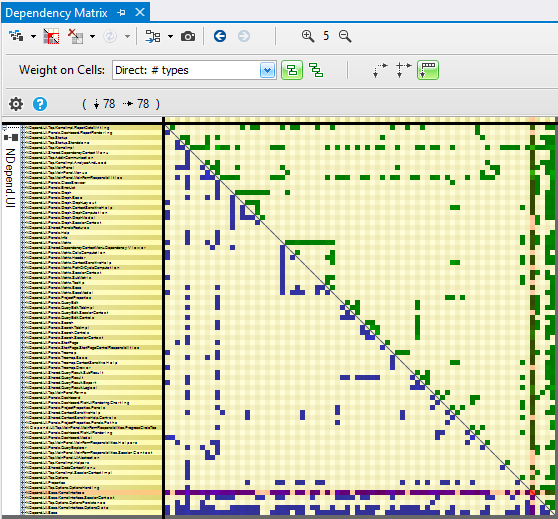
When it comes to dependencies visualization in a code base the usual boxes and arrows dependency graph is the royal kind of diagram to use. However for a long time we favored the Dependency Structure Matrix (DSM) shown in the next section. DSM is less intuitive but it scales better on large code base. For example in the picture below the DSM shows at a glance that the structure is layered because there is no cycle aggregated around the matrix diagonal. Also it shows that some elements are more used than others through horizontal blue lines. The graph on the right is quite unreadable and doesn’t provide such information.

We favored DSM over graph until we discovered in 2019 a way to draw meaningful and usable graphs made of hundreds or thousands of elements. This finding led to the NDepend version 2020.1 relifted graph released in April 2020. The graph improvements are:
- Children graphs are nested within boxes of parent graph (recursive)
- Boxes area is proportional to the size of the element represented (expressed in number of lines of code)
- A color scheme does highlights dependents of the element selected or hovered
- The graph scales on the largest code base and can displays live hundreds of thousands of elements (more on this below)
- Many tools are proposed to navigate code through one-click graph generation.
The graph below shows the structure of the code of the dependency graph itself. The class GraphController is selected. Mutually dependent classes are in red, classes used directly are in blue and classes used indirectly are in light blue. Edges are also colored accordingly and dashed edges are used to indicate indirect dependency. Here see this graph exported to SVG vector format, expanded till the method level.

There are many tools to visualize software architecture through dependency graphs but our implementation scales live on large code bases with thousands of elements. See below a graph made of the 15.000 classes of .NET 7.0 zoomed live.

Plenty of features are proposed to quickly obtain the right perspective the developer needs to study some code. One of my preferred is the search feature. For example below in the NopCommerce code base we search all namespaces related to the entity customer. Then we filter and expand them.

Visualizing the internal structure of components and how they interact each other is the natural way of using a dependency graph to visualize architecture. However several other useful graphs can be generated and then browsed.
Coupling Graph
Double clicking an edge between two components shows which classes and methods from both components are involved into the coupling.

Call Graph
With a single click the user can generate a graph made of direct and indirect callers and callees of an element.

Graph of entangled code
Some heuristic are proposed to locate and then visualize entangled area in code.

When Code Visualization leads to Code Navigation
With all these features the dependency graph is not just a tool to visualize code but also a tool to navigate code. Developers spend a significant portion of their days navigating code. Modern IDEs like Visual Studio offer plenty of ways to browse code (detailed in this post 10 Visual Studio Navigation Productivity Tips). Being able to generate any graph live in a few clicks from the code editor, the solution explorer or anywhere else in the IDE increases the developer productivity in many scenarios.
A lot more can be said about visualizing architecture through dependency graph but I want to keep some spaces in this post for other diagrams. You can refer to this documentation and watch this 6 minutes video:
Dependency Structure Matrix (DSM)
As explained above, DSM had been our favored way of visualizing architecture until we relifted the dependency graph that now makes it a better choice in most scenarios. DSM is less intuitive than graph but its strength is that it lets spot complex patterns at a glance. In the first screenshot above we saw that layered code, high level and low level components, can be easily identified. The same way the DSM relies on an heuristic to naturally group rows and columns to highlight dependency cycles. In the below matrix:
- Black cells means that both elements in row and column are mutually dependent.
- Blue cell means that the element in column uses the element in row. The weight on cell is the number of types involved.
- Green cell means that the element in row uses the element in column.

Below is the same structure visualized with graph. Clearly on such super-entangled structure the DSM view is more readable.

Here are some other scenarios where the DSM can help:
High-Cohesion and Low-Coupling
Identify areas in code with High-Cohesion and Low-Coupling. Such pattern provokes some squares aggregated around the diagonal.

Components that is using many other components
Such component is identified by the highlighted column with many blue cells. Typically such code can be dependency injection code: code that binds many classes from many components with their implementations.

Popular components
A popular components is identified through the highlighted row. This can be the class String or the namespaces System used almost everywhere in code for example.
To know more about the NDepend DSM you can watch this 5 minutes videos and refer to the DSM documentation.
Heat-Map and Treemap
When treemap was invented in the early 2K’s it fascinated me. Treemaping is a way to visualize metrics and hierarchical data. NDepend has been one of the first tool that uses treemap to visualize code. The tool can now display 2 code metrics at the same time. This is especially useful to visualize code coverage data. In the screenshot below:
- Small rectangles are methods of the NDepend code base. The rectangle area is proportional to the method number of lines of code (the Size Metric).
- Larger rectangle are the code hierarchy: classes, namespaces and projects that group their child elements.
- The color of a method rectangle represents the percentage of code coverage ratio (the Color Metric).
This view instantly tells us that the overall coverage is quite high (actually 86.5%) and pinpoints areas that need more testing efforts.

This Code Metric View is also useful to pinpoint too complex code and to highlight code query result. You can refer to the documentation and watch this 4 minutes video:
The Abstractness vs. Instability Diagram
One great software book is Agile Software Development, Principles, Patterns, and Practices written by Robert C. Martin (Uncle Bob) in 2002. In this book R.Martin exposes the Dependency Inversion Principle (DIP), one of the famous SOLID principles. This principle states:
a. High-level modules should not depend on low-level modules. Both should depend on abstractions.
b. Abstractions should not depend on details (concrete implementation). Details should depend on abstractions.
From this defininition R.Martin deduces some metrics:
- Abstractness within the range [0,1]: If a component contains many abstract types (i.e interfaces and abstract classes) and few concrete types, it is considered as abstract.
- Instability also within [0,1]: A component is considered stable if its types are used by a lot of types from other components. In this context stable means painful to modify.
The Abstractness versus Instability Diagram helps to detect:
- Which components are potentially painful to maintain (i.e concrete and stable). For example imagine modifying the implementation of the class string used by the entire world. The chances to break some clients is high and you would have to be super careful. Welcome to the Zone of Pain.
- Which components are potentially useless (i.e abstract and instable). For example imagine an interface used and implemented by almost nobody. This is the Zone of Uselessness.

Code Querying
During our researches in the early days of NDepend we quickly realized that code visualization is great and useful, but it cannot let the user browse all dimensions of the code. By code dimensions I mean artefacts like:
- code size
- code complexity
- code coverage
- code hierarchy (projects contain namespaces that contain classes that contain members)
- code dependencies,
- usage of OOP concepts (inheritance, virtual methods, encapsulation…)
- state mutability (assigning a field, immutable class, pure method…)
- identifiers and naming
- delta between the actual snapshot and a baseline snapshot
- source files organization
- trending
- …
The idea of considering code as data needed to be pushed a little more to imagine that all those dimensions could be queried the same way relational data is queried through SQL. This led first to CQL Code Query Language, that had been quickly refactored to CQLinq Code Query over C# LINQ shortly after the LINQ revolution era early in the 2010’s.
Mixing dimensions within a code query is quite useful. For example in the screenshot below we spot classes added or refactored since the baseline and not 100% covered by tests. This is quite useful information. More generally focusing on code smells introduced since the last release is a powerful way to get used to write better code.

CQLinq quickly became the backbone of the tool and all architecture diagrams explained above are based on it. For example one useful feature is to export elements matched by a code query to the dependency graph or dependency matrix.
Most of code queries are generated so the user can be productive without learning CQLinq up-front. Also CQLinq makes possible many other use-cases than just code visualization including: code rules, smart technical-debt estimation, quality gates, reporting, trend charts, code search, audit legacy code, prioritize hot-spots to fix first, API breaking changes detection… This led the community to re-name the tool as the swiss-army-knife for the .NET developers.
Other Potential Ways to Visualize Software Architecture
One promising way to visualize code would be to use 3D. There exists some interesting initiatives like Code City by Richard Wettel in 2008 but these researches never led to an industry standard 3D tool.

Using circle visualization has been also an area of research but to my knowledge it has never been well suited to visualize code. The key is to really add value over existing software visualization technologies.

Conclusion
In this post I explained some key ideas and decisions we took within the last 15 years. Today our tool-belt helps thousands of developers worldwide to better understand what they do and thus, write better code. Moreover one of the most rewarding experience when developing a tool for developers is to dogfood it. Being the first users of all these features is quite an intresting position.
More than ever the development technology landscape is evolving quickly, especially in the .NET sphere. The challenge is to be present where the developers are and prepare where they will be. This will mean quite a lot of refactoring for us, like for example to adapt our UI to propose a web or a multi-platform experience. Fortunately thanks to abiding by our own advices during all these years mean that our code is now well fitted to let us handle these challenges confidently.