
About a month ago, I wrote a post about how unit tests affect (and apparently don’t affect) codebases. That post turned out to be quite popular, which is exciting. You folks gave a lot of great feedback about where we might next take the study. I’ve incorporated some of that feedback and have a followup on the unit test effect on codebases.
Summarized briefly, here are the high points of this second installment and refinement of the study:
- Eliminating the “buckets” from the last time.
- Introducing more statistical rigor.
- Qualifying and refining conclusions from last time.
Also, for the purposes of this post, please keep in mind that non-incorporation of feedback is not a rejection of that feedback. I plan to continue refinement but also to keep posting about progress.
Addressing Some of the Easier Questions and Requests
Before getting started, I’ll answer a few of the quicker-to-answer items that arose out of the comments.
Did your analysis count unit test methods when assessing cyclomatic complexity, etc.?
Yes. It might be interesting to discount unit test methods and re-run analysis, and I may do that at some point.
Can you show the code you’re using? Which codebases did you use?
The scraping/analysis tooling I’ve built using the NDepend API is something that I use in my consulting practice and is in a private repo. As for the list of specific codebases, I’m thinking I’ll publish that following the larger sample size study. In the most general terms, I’m going through pages like this that list (mostly) C# repos and using their links.
What about different/better categorization of unit test quality (test coverage, bolted on later vs. written throughout vs. demonstrably test driven)?
This is definitely something I want to address, but the main barrier here is how non-trivial this is to assess from a data-gathering perspective. So I will do this, but it will also take time.
Think of even just the anecdotally “easy” problem of determining TDD vs. non-TDD. I approximated this by positing that test-driving will create a certain ratio of test methods to production methods since any production method will be preceded by a test method (notwithstanding future extract method refactorings). We could, perhaps, do better by auditing source control history and looking for a certain commit cadence (modification to equal numbers of test/production classes, for instance). But that’s hard, and it doesn’t account for situations with large batch commits, for instance.
The upshot is that it’s going to take some doing, but I think we collectively can figure it out.
Unit Test Study Refinement Overview
One of the most common suggestions, not surprisingly, was to incorporate a larger sample size. That’s in progress. As of this writing, I now have 225 codebases and counting, and I’m hoping to get to 500 or 1,000 before rerunning the analysis. But none of today’s refinement involves those new codebases.
Instead, here’s the feedback (paraphrased) that I will address, either completely or partially, in this post:
- Change the distribution of/eliminate the buckets.
- Perform some statistical analysis on the findings.
- Start accounting for total lines of code in the codebases.
Getting a Little More Statistical
I should say, at this point, that I’m not a statistician by trade. I took some college coursework in stats and wrote some white papers in grad school, but I’m a lot of things before a statistician: programmer, consultant, writer, etc. So to make things better, I did what anyone with too many irons in their fire ought to do: I enlisted help.
I have a business partner that has more recent experience with statistics than I do, and he also has access to statistical modeling tools. So I partnered with him to analyze the raw data. Again, neither of us are statisticians by trade, but the idea is to learn, tighten up the findings, and get more rigorous as we go. So we did regression analysis to see what we’d find.
Today, we have unit test data scatter plots and two interesting new pieces of information: r values and p values. If these terms are mysterious to you, let me, as a neophyte having just learned, explain in simple terms. I’ll also include what I measured last time, which was, in effect, the slope of the relationship.
- Slope is simply the relationship quantified. For instance, “Parameters per method decrease as unit test percentage increases.”
- r values measure “How much of variable A‘s behavior does variable B explain?” on a scale of 0 to 100%. For instance, “Unit test percent explains 34% of the variance in parameters per method.” (This applies, of course, only to the variables that we included in our study)
- p values measure “How likely is it that the ostensible, observed relationship doesn’t actually exist?” For instance, “There’s a 0.06% chance that unit test method percent has no effect on parameters per method.”
Observations From Last Time
Alright. With explanations out of the way, let’s briefly reexamine what I initially posted, using the “buckets” that I’d created and corresponding graphs (color-coded according to relationship with conventional wisdom).
- Cyclomatic complexity increases as unit test method percent increases.
- Lines of code per method increases as unit test method percent increases.
- Nesting depth stays flat across changes in unit test method percentage.
- Method overloads decrease as unit testing percentage increases.
- Parameters per method decrease as unit testing percentage increases.
- The number of interfaces decreases as unit test method percentage increases.
- Inheritance decreases as unit test method percentage increases.
- Cohesion increases as unit test method percentage increases.
- Lines of code per type stay the same as unit test method percentage increases.
- Types have fewer comments as unit test method percentage increases.
Just because it struck me during subsequent analysis, I also took a look at the number of lines of code per constructor as well, reasoning that this would tend to be lower in codebases with more tests.
Let’s see some visuals now as to how all of this plays out in the refined study.
Method Cyclomatic Complexity as a Function of Unit Test Method Percentage

In the last round, my trend chart using the buckets had method cyclomatic complexity trending upward as unit test method percentage increased. Getting rid of the buckets eliminated this relationship. Indeed, the slope is as close to flat as possible. But beyond that, take a look at the P value — there’s a 97% chance that no relationship exists between these variables.
Conclusion: unit test method percent and cyclomatic complexity appear unrelated.
Lines of Code Per Method as a Function of Unit Test Method Percentage

Unfortunately, this time around we don’t see more favorable results for unit testing by “de-bucketing.” There’s a visible slope showing that average method lines of code increases as unit test percentage increases. The p value also indicates that there’s roughly an 80% chance that these variables relate. And while the r value says that a lot of other stuff affects method lines of code, it does appear that unit test method percentage hurts it.
Conclusion: unit test method percent correlates with an increase in lines of code per method.
Nesting Depth as a Function of Unit Test Method Percentage

As one might expect, the relationship with nesting depth looks a lot like the one with cyclomatic complexity. (Meaning cyclomatic complexity and nesting depth are probably quite related.)
Conclusion: no relationship.
Number of Method Overloads as a Function of Unit Testing

This graph has some fairly extreme outlier points at the lower end of the test method percent spectrum, and it stabilizes a bit as you get more unit tests. There’s a clear inverse correlation here, and the p value is decent — a basketball free throw.
Conclusion: more unit test method percent means fewer method overloads.
Number of Method Parameters as a Function of Unit Testing

Now, this is a pretty convincing relationship. Unit test percentage explains about a third of the variance in number of parameters per method, and the p value is vanishingly small. These are definitely related.
Conclusion: more unit test method percentage correlates with fewer method parameters.
Percent of Interfaces as a Function of Unit Testing
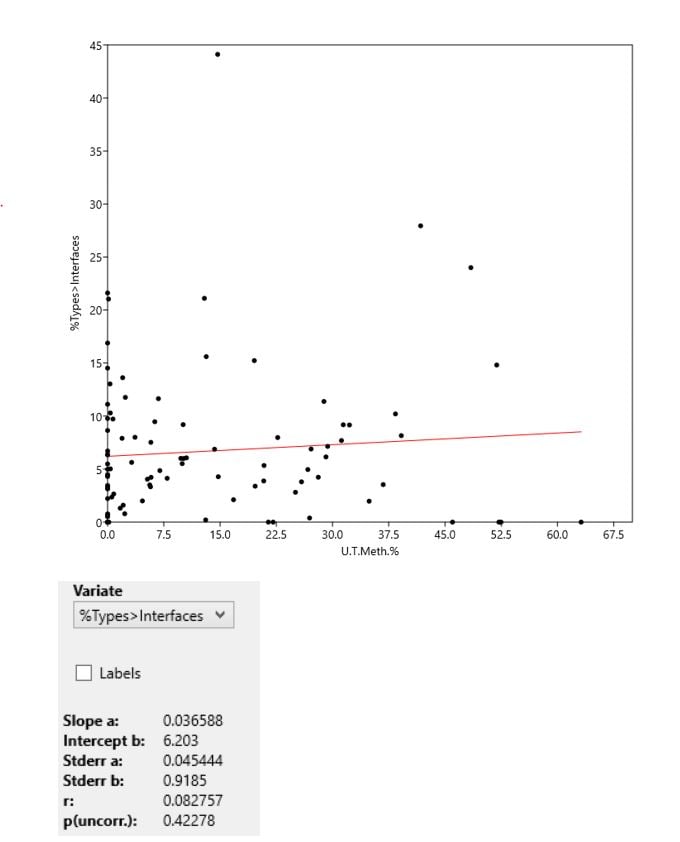
This is another one where it was good to get rid of the buckets. It appears that, inasmuch as we can infer a relationship here, that relationship appears to positively correlate the number of interfaces with the percent of unit test methods. That said, the p value is creeping toward a toss-up as to whether this relationship meaningfully exists or not.
Conclusion: It’s hard to infer too much about this relationship.
Average Inheritance Depth as a Function of Unit Testing

Here, we have another definite relationship, as evidenced by the 0.2% p value.
Conclusion: more unit testing definitely correlates with less inheritance.
Type Cohesion as a Function of Unit Testing

Now, for this one, remember that we’re actually looking at a graph of “lack of cohesion,” so you need to invert your thinking. Again, here we have pretty convincing p value and r value as well as a visible slope relationship. Unit testing correlates negatively with lack of cohesion.
Conclusion: unit test method percentage correlates with type cohesion.
Lines of Code Per Type as a Function of Unit Testing

This relationship is more likely uncorrelated than not, and both slope and r absolute values are near zero, with perhaps a slight trend downward on the graph.
Conclusion: there’s a pretty good chance that unit test method percentage and type size aren’t related.
Comments Per Type as a Function of Unit Testing

In a development that will surprise few, higher percent unit test codebases seem to correlate with fewer comments per type. The p value gives this relationship about an 85% chance of being significant, and there’s a definite negative slope there.
Conclusion: more unit test method percent correlates with fewer comments in your types.
Lines of Code Per Constructor as a Function of Unit Testing

Here we see a negative slope, meaning more test percentage seems to correlate with fewer lines of code per constructor, on average. The p value is around one-third, though, so we can’t be overly confident in this one.
Conclusion: there’s a decent chance higher unit test method percentage correlates with fewer lines of code per constructor.
Codebase Sizes
I also mentioned that I’d add this variable into the mix. We did that, keeping track of codebase total LOC, where I hadn’t had that in there before. Plotting it out also told me that this study skews heavily toward small codebases.

The largest codebases in this corpus are around 100K lines of code. Not trivial, but also not representative of some of the behemoths you see in the enterprise. So another thing on the to-do list is to figure out how to land some big game codebases.
Until Next Time
This is by no means the end of this series. We’re starting to dabble in more rigor on the statistics side of things here, so, as with last time, suggestions are welcome.
Please bear in mind that nothing here is (yet) intended to be a white paper or to look like a PhD thesis. Rather, the idea is to start a conversation about gathering codebase data and starting to study it. I’m hoping that we can start bringing more facts and data and fewer anecdotes to bear when talking about how to write software.
So stay tuned. If you want to follow along with the series, your best bet is to subscribe to the NDepend blog’s RSS feed. Next month, we’ll see how the conclusions hold up with significantly more codebases in the mix.
Thanks a lot, that’s very interesting. I’m wondering if unit testing or TDD in particular has an effect on the number of getter/setters. Especially setters, I create less of them when I code using TDD.
I actually captured “percent of codebase methods that are properties” in my data, so I just took a look. I don’t have access to the stats software, so no r or p-values, but the trend line is decidedly negative. In other words, it appears that you’re exactly right — more unit tests correlate with fewer getters and setters.