
It’s been about a month since my last research post, and I’ve been musing about the next topic. What should it be? Well, I’ve decided. Since I love nothing more than throwing the gates wide for everyone’s internet anger, I thought I’d weigh in on the subject of self documenting code vs comments.
I’ll be awaiting your rage below, in the comments.
Self Documenting Code vs. Comments: The Controversy
For those of you not privy to this hotly debated topic, I’ll summarize it briefly. People that feel strongly about this topic comes down on one of two sides:
- You should always comment your code so and keep your comments up to date so that maintainers understand your intent. There’s no substitute for documentation.
- Instead of writing comments, which can become out of sync and misleading, you should strive to make comments unnecessary by writing so-called self documenting code. Everything about the code is clear from simply looking at it and the unit tests that exercise it.
In the end, it comes down to a difference of opinion about whether or not to include code comments.
Pro-comment folks tend to view claims of “self documenting code” to be exaggerated and often an excuse for not bothering to document. They think of their non-commenting counterparts as lazy or obstinate.
Folks in the self documenting code camp tend to ignore comments written by others, since, as they’ll point out, comments can lie. And since comments are just noise to them, they don’t bother writing them. And, what’s more, they don’t particularly enjoy commenters accusing them of laziness or trying to alter their behavior.
As you might imagine, flame wars predictably ensue.
Let’s See What the Data Says: Comments and Self Documenting Code
It seems like a logical thing to do is to look at clean code properties of codebases and see how they relate to prevalence of code comments. And we may do that at some point.
But today I’m starting a little more humbly.
A bit of precursor research to the value of comments (or lack thereof) is to try to look at the relationship between comments and self documenting code. Do these things coexist or, as a party to the endless flame wars might posit, do they have an inverse relationship?
Let’s find out.
The Study and Its Caveats
As with the previous studies, we’re conducting this research on more than 500 .NET codebases mined from Github. We use the NDepend API to gather all sorts of information about them, and then we run regressions and statistical analysis to look for interesting trends and relationships.
In this case, we’re going to need to capture data that indicates code comment prevalence and “self-documenting code” prevalence.
First up, let’s consider code commenting prevalence. NDepend actually directly captures this data, so that’s nice and easy.
Self documenting code, on the other hand, is a pretty hard concept to capture. In the first place, it’s entirely subjective and in the eye of the beholder. And secondly, even if you distilled it to some concepts, what would those be, and how would you capture them as data?
Well, here’s what we went with: name length. People striving for self documenting code do any number of things, but one pretty universal approach that you see is to create highly detailed (and thus long) names. We may later run an analysis that factors in things like unit testing prevalence, methods per type (refactoring to many succinct methods, etc.). But for now, the risk of over-complicating seems high before seeing what the data says.
Believe me, I understand that this is an oversimplification. But it’s a step in the right direction and away from the “nothing” we have now, data-wise. And these posts are about sparking discussions and directing further research—not publishing in scientific journals.
The Relationship Between Code Comment Percent and Method Name Length
So we took these hundreds of codebases and examined how the name length corresponded with prevalence of comments in methods. And here’s a visual of what we found.
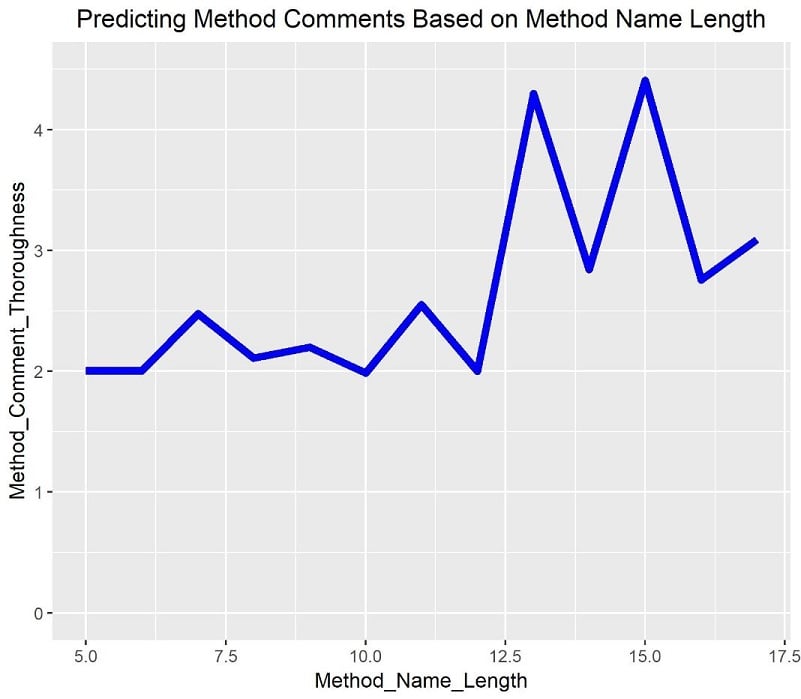
As you can see, this is not a linear relationship. My partner, whose forte is statistics and data science, ran a non-parametric, k-nearest neighbor analysis and determined that there’s something of a binary relationship. Here’s how it works.
- Below average method names of roughly 13 characters, name length has little bearing on the prevalence of comments.
- Above 13, changes in method name length also have little bearing on the prevalence of comments.
- But, when you bucket codebases into “average method name of less than 13” and “average method name of greater than 13,” you have a situation where the latter bucket comments at about twice the rate of the former.
I honestly did a double take when I saw these results. It was not what I had expected, in a couple of ways.
People Really Don’t Comment Very Much
First of all, wow, on the commenting amount. Code comment percentage answers the question “what percentage of all lines have comments?” And we’re talking about a bucket of around two percent and around four percent.
This means that across all of these codebases, we’re talking about three percent of lines involving code comments. That’s a good bit less than I’d have expected in aggregate. And I’d have thought that the number might be dragged up by the occasional maniac commenting every line or something. But no, not really. People just don’t do much inline commenting.
Part of this could be that we’re looking entirely at open source codebases. I don’t know this for sure, but I’d imagine that open source codebases feature sparser commenting than their corporate counterparts for a variety of reasons.
But even with that caveat, this is a small figure. People just don’t seem to comment very much. So for those of you screaming at everyone to comment more, it doesn’t appear that anyone is really listening.
More Descriptiveness Means More Comments? Perhaps the Controversy is Overblown
Even more interesting, however, than the sparseness of comments is the relationship. The people that write longer (and thus presumably more descriptive) names are the same people that write comments at twice the rate of their terser counterparts.
Given the controversy, I was fully expecting an inverse relationship that was perhaps linear. The longer your names for things, the fewer comments you write. But that didn’t happen at all. And this suggests that this apparent controversy might, in fact, be quite overblown.
Perhaps it’s just a loud handful with passionate feelings that are duking this out. Meanwhile, the rest of the world quietly says “why not try to write self-documenting code and add comments where I think they might help.” And, at the risk of the appeal to moderation fallacy, I’d say that actually sounds like a pretty good idea.
I look forward to researching this further and finding perhaps more complex ways to represent self documenting code and to study how both of these things correlate with other codebase properties. But, in the meantime, it might be that you don’t necessarily need to pick a side in this particular battle.
Nice research! I am a bit in both camps although I find myself moving towards the less-comments camp. The reason is mainly that there is only one thing worse than missing comments and that is false comments. So I started to cut down on method / procedure length. And I found an interesting correlation between nr of variables needed and procedure length; the shorter my procedures are, the less variables I need. When refactoring some old code and moving code to new (shorter) procedures, I sometimes am able to reduce the nr of vars with 80-90%
I am curious if you can do an analysis of procedure/method length vs number of variables (variables, not parameters) since I suspect that there may be a relation as well.
Interesting. That’d be another one that I’d assume would be a no-brainer: number of variables would vary at least linearly with method length. But I’ve been wrong before about supposed no-brainers, so it’d be an interesting piece of research to do, either on its own, or as part of a larger collection of inquiries.
Thanks for the idea!
Considering most code I read has comments only on the method headers, I’d be interested how many methods, functions or classes are commented – assuming that many people don’t bother commenting inline, because that’s WHAT the code does, but they’ll comment the class, method or function because that’s showing WHY the code does things in the way it does…
Interesting thought, thanks. I’ll have to look at a good methodology for differentiating inline and header/API-style comments.