
In case you haven’t seen it, I’ve been doing a series of research-oriented posts for this blog. This is going to be in the same vein but focused on the Moq codebase instead of focusing on hundreds of codebases. Why Moq? Well, I’ll get to that in a moment.
I started this by making a set of observations relating unit test prevalence to properties of clean code. That generated considerable buzz, so I did some more studies in that vein, refining the methodology and adding codebases as we went. By the end of the series, we’d grown the sample size to 500 codebases and started doing actual regression analysis.
Since then, we’ve enlisted the help of someone who specializes in data analysis to do some PCA with the data, which far outstrips my background studying data. We brought this to bear in studying the effects of functional-style programming on codebases and also on categorizing codebases according to simple vs. complex and monolithic vs. decoupled, in addition to functional vs. OOP. Doing this across more than 500 C# codebases has produced a wealth of information.
Okay, But How Does Moq Fit in?
I give you all this backstory in case you want to read about it but also to explain that I’ve looked at these codebases en masse. With hundreds of codebases and millions of lines of code, I’m not going in and poking around to see if the code looks clean. I’m using NDepend to perform large-scale robo-analysis.
And, while that’s been great, I started to want to see just how these categorizations stacked up. So I started scrolling through the summary data and Moq jumped out at me.
First of all, I know Moq pretty well from using it over the years, and secondly, it had stood out when looking at the rate of unit test methods in the codebase. Nearly half of its methods are test methods, which seems reasonable for a tool designed to help you write unit tests. Combine that with these stats in the PCA:

So as a quick interpretation, Moq counts as reasonably non-monolithic, very simple, and very functional. Add to that the high degree of unit testing, and I figured we’d have a codebase that was a joy to look at. So I popped open the source code (as it was at the beginning of the year when I was grabbing codebases en masse) and analyzed it with NDepend, fresh off my excitement about using the new dark theme. I wanted to see if it was as much of a joy to look at as all of this data and statistical rigor indicated it would be. And spoiler alert, it was the kind of codebase I’d feel right at home in. Let’s take a tour.
NDepend Analysis, Test Coverage, and First Look
The first thing I wanted to look at was code coverage. This was because I wanted a quick test case to see if my assumption that a high rate of test methods would correspond to high coverage. And, it did. Here’s a quick look at what happened after I imported coverage data and then ran analysis on the project.

Now I could see with Visual Studio’s coverage tool itself that Moq was sporting roughly a 90% test coverage. But by importing the coverage data into NDepend, you can paint a much more compelling picture.
The heat map dominating most of the screen shows squares corresponding to methods in the codebase. Larger squares are larger methods. And the coloring indicates test coverage. Over on the right, among the 2,152 methods in question, you can actually scroll through them in order of percent coverage and navigate to them if you want to take a look.
Taking a Look at the Dashboard and Technical Debt
So far, all systems go. Most of the stats on the codebase looked good, coming in from the broad aggregates I have in a spreadsheet. And then, following the same trend, Moq looks great in the IDE from a testing perspective. But I looked at the dashboard and saw this:

Basic stats about the codebase lined up, and there’s the test coverage, hovering around 90%. But a C for its tech debt rating? 10 critical rules violated? This surprised me, given how rosy everything looked in the statistical analysis. I drilled in to take a look.
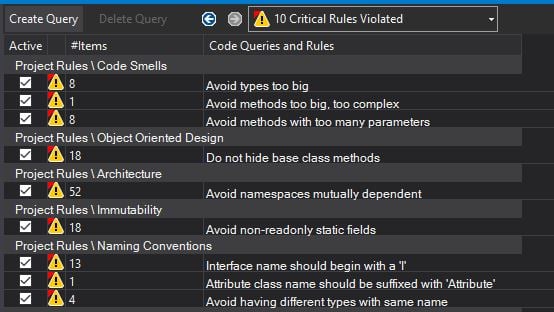
And, sure enough, there be some dragons. Huge types and overly complex methods are a problem. Also in there are mutually dependent namespaces, which create coupling that hurts you as a codebase grows. And you’ve got some hiding of base class methods and global state. To get a sense for what I was looking at, I created another heat map. In this case, we’re looking at types. The bigger the square, the more lines of code, and the closer to red, the more methods in that type.

This explains why the averages looked good in my spreadsheet but why NDepend has some objections and critical rules violated. By and large, you have a lot of little green types, which is what you’d hope to see. But there are some pretty hefty types in the mix, both in terms of lines of code to the type and number of methods to the type.
Some of these are gigantic unit test classes, while others are the API. For those of you familiar with Moq, this should make sense to you. Think of how many static methods you invoke on the Mock class. This illustrates the classic tradeoff between shooting for clean code guidelines about methods per type and such and between providing the API you want to furnish.
Drilling Into the Sources of Debt
NDepend has a view where you can drill into the technical debt per type or per method, and sort it accordingly. I did that per type, and here’s what I saw:

No big surprise there. The technical debt was coming disproportionately from these large types. So I took advantage of another view to see where the debt was coming from, by rule violation. Here’s what that looked like:

Topping that list is a series of things that I would make it a priority to address in my own codebases, time permitting: types that are too big, types that have too many methods, namespace dependency cycles, and so on. There is, however, one exception to what I would worry about as a top priority issue—visibility of nested types as a design choice. That’s based on a Microsoft guideline and I don’t personally favor an approach where I use this a lot. But it doesn’t bother me, either.
I see that the creators of Moq did that 395 times, so clearly they view it as a useful design choice. This made me curious about what would happen to the tech debt grade if I disabled that particular rule. So I did that, and the result was a somewhat greener and more pleasing grade of B:

What’s the Verdict With Moq?
I also spent some time scrolling through various classes and methods. I didn’t want the entirety of the experience to be just a matter of data gathering since that’s what I’ve been doing for months. And the verdict I have is that this particular data point fits in nicely with the aggregate.
Moq has excellent stats for most of what I’ve been looking at. And, indeed, there are a lot of simple, functional methods in the codebase, almost all of which are thoroughly tested. I would happily work in this codebase.
But NDepend is calling out real and important opportunities for improvement. If I were working on this codebase, I’d make an effort to break some of those gigantic unit test classes into smaller ones that are more cohesive over their context. I’d also take a hard look at the mutually dependent namespaces and either merge them or rework the dependency direction a bit. And even I’d give some idle thought to how I might segment the large Mock class somehow into smaller chunks if that wound up making sense.
So the whole thing winds up being an interesting microcosm to me. Moq is, as the stats would indicate, a pretty nice codebase. But, as with just about any codebase, there’s plenty of room for improvement. And having a tool to show you where to improve quickly is invaluable.
I enjoyed this very much. What intrigues me is how you can have two organizations developing software – both are doing the same thing – but one sees the value of metrics and analysis while the other doesn’t even know that they exist. Paid tools like NDepend couldn’t exist if no one got value from them. It costs less than two days of a developer’s time which we can easily burn through fixing a few bugs or making what should be a small change to a 3,000-line class. I don’t understand the gap between paying for decent analysis and not knowing that there is such a thing.
Glad you enjoyed, and well put. It always leaves me a little dumbfounded when development organizations wring their hands over tools that are a few hundred dollars, but would help the team enormously and yield ROI more or less on day 1.