I’ve been letting the experiments run for a bit before posting results so as to give all participants enough time to submit, if they so choose. So, I’ll refresh everyone’s memory a bit here. Last time, I published a study of how long it took, in seconds (self reported) for readers to comprehend a series of methods that varied by lines of code. (Gist here). The result was that comprehension appears to vary roughly quadratically with the number of logical lines of code. The results of the next study are now ready, and they’re interesting!
Off the cuff, I fully expected cyclomatic complexity to drive up comprehension time faster than the number of lines of code. It turns out, however, that this isn’t the case. Here is a graph of the results of people’s time to comprehend code that varied only by cyclomatic complexity. (Gist here).
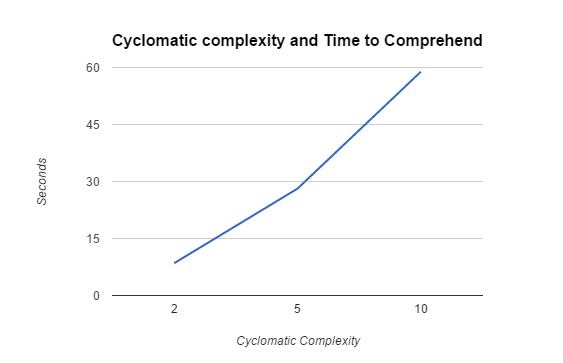
If you look at the shape of this graph, the increase is slightly more aggressive than linear, but not nearly as aggressive as the increase that comes with an increase in lines of code. When you account for the fact that a control flow statement is also a line of code, it actually appears that conditionals are easier to comprehend than the mathematical statements from the first experiment.
Because of this finding, I’m going to ignore cyclomatic complexity for the time being in our rough cut time to comprehend metrics. I’ll assume that control flow statements impact time to comprehend as lines of code more than as conditional branching scenarios. Perhaps this makes sense, too, since understanding all of the branching of a method is probably an easier task than testing all paths through it.
As an aside, one of the things I love about NDepend is that it lets me be relatively scientific about the approach to code. I constantly have questions about the character and makeup of code, and NDepend provides a great framework for getting answers quickly. I’ve actually parlayed this into a nice component of my consulting work — doing professional assessments of code bases and looking for gaps that can be assessed.
Going back to our in-progress metric, it’s going to be important to start reasoning about other factors that pertain to methods. Here are a couple of the original hypotheses from earlier in the series that we could explore next.
- Understanding methods that refer to class fields take longer than purely functional methods.
- Time to comprehend is dramatically increased by reference to global variables/state.
If I turn a critical eye to these predictions, there are two key components: scope and popularity. By scope, I mean, “how closely to the method is this thing defined?” Is it a local variable, defined right there in the method? Is it a class field that I have to scroll up to find a definition of? Is it defined in some other file somewhere (or even some other assembly)? One would assume that having to pause reading the method, navigate to some other file, open it, and read to find the definition of a variable would mean a sharp spike in time to comprehend versus an integer declared on the first line of the method.
And, by popularity, I mean, how hard is it to reason about the state of the member in question? If you have a class with a field and two methods that use it, it’s pretty easy to understand the relationship and what the field’s value is likely to be. If we’re talking about a global variable, then it quickly becomes almost unknowable what the thing might be and when. You have to suck the entirety of the application’s behavior into your head to understand all the things that might happen in your method.
I’m not going to boil that ocean here, but I am going to introduce a few lesser known bits of awesomeness that come along for the ride in CQLinq. Take a look at the following CQLinq.
|
1 2 3 4 5 6 7 8 9 10 |
// Method fields and parameters used JustMyCode.Methods.Select( m => new { m, Parameters = m.NbParameters, FieldsUsed = m.FieldsUsed.Count(), FieldsAssigned = m.FieldsReadButNotAssigned.Count() } ) |
If your reaction is anything like mine the first time I encountered this, you’re probably thinking, “you can do THAT?!” Yep, you sure can. Here’s what it looks like against a specific method in my Chess TDD code base.
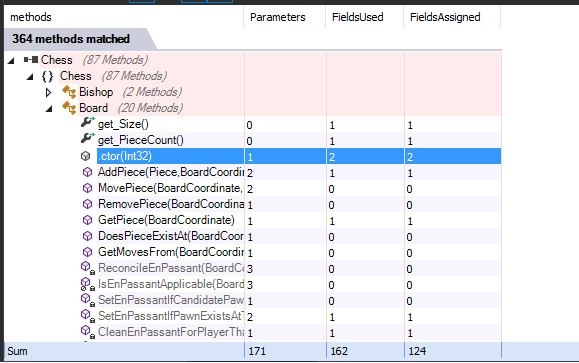
The constructor highlighted above is shown here:
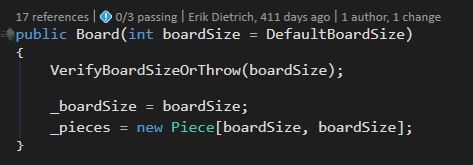
As you can see, it has one parameter, uses two fields, and assigns both of those fields.
When you simply browse through the out of the box metrics that come with NDepend, these are not the kind of things you notice immediately. The things toward which most people gravitate are obvious metrics, like method size, cyclomatic complexity, and test coverage. But, under the hood, in the world of CQLinq, there are so many more questions that you can answer about a code base.
Stay tuned for next time, as we start exploring them in more detail and looking at how we can validate potential hypotheses about impact on time to comprehend.
Comments are closed.