If you’ve been keeping track, you’ll noticed that it’s been a while since the last post in this series. In case you’d forgotten or lost track, the primary goal is to build a composite metric experimentally. I’ve been looking to work experimentally toward a “time to comprehend” metric. The series also has a secondary goal, which is to take a tour of NDepend and see how it and static analysis in general work.
To lay my cards on the table, the reason I haven’t picked the series back up is a data-based one. Simply put, not a lot of people read them, and the readership has waned since the beginning of the series. On the bright side, the experiment has attracted a small, loyal following of people that participate in the code experiments, but that seems to be about it for the audience. I’ve mulled over the reasoning for these posts not doing as well as the other posts I make to the blog, but, at the end of the day, the data is the data, and my main interest is providing the readership with material that interests you.
Because of this, I’m going to draw the series to a close before I had originally intended to do so. Don’t worry — I’m not just going to abruptly call it a day. Rather, I’m going to take the progress that we have made and turn it into a rough stab at a tentative, composite metric. From there, I’ll call for one last experiment to see how that metric does.
A Quick Review of the Time to Comprehend Metric
For a more detailed look back, you can check out all of the posts in the category. I originally formed a series of hypotheses in one of the early posts, and then set about conceiving of experiments around some of them. The hypotheses related to naming quality was something that I never touched, and would be extremely non-trivial to measure, so I was planning to build to those. In the interim, I addressed some more tangible, easily measured considerations.
- How many lines of code does a method have?
- What is the cyclomatic complexity of a method?
- How many parameters does a method have?
- How many local, class-level, and global variables does a method have?
In addition to orienting posts around discussing and measuring these concerns, we ran a couple of experiments that included reader feedback. Those experiments explored time to comprehend a method as a function of (logical) lines of code in that method and the cyclomatic complexity. As it turned out, the time to comprehend increased more than linearly with the number of lines of code in the method. In other words, each line of code added to a method takes more incremental time to understand. This makes some intuitive sense, since the lines of code in a method are often inter-related.
A more surprising find was that time to comprehend actually varied more with lines of code than it did with cyclomatic complexity. Cyclomatic complexity is the number of paths through a method, meaning that cyclomatic complexity increases with the number of control flow statements in a method. Cyclomatic complexity creates a heavy burden on testing and reasoning about code since it creates additional scenarios, but, in spite of that, time to comprehend actually increased faster as a function of lines of code than cyclomatic complexity, apparently indicating that comprehension of a given control flow statement is more impacted by it being a line of code.
Because of this, I chose to omit cyclomatic complexity from the calculations of experimental results and this is the most recently computed attempt to fit a curve to experimental data.
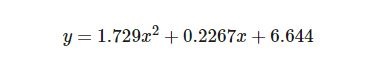
Adding More To The Mix
This is a quadratic function of time to comprehend as a function of x, the number of lines of code. Let’s speculatively introduce parameters and scope to the equation to see if we can’t get at least a little closer before we wrap up the series. To arrive at a formula, I’ll introduce the following hypotheses.
- Reasoning about a method parameter is roughly as time consuming as reasoning about a line of code.
- A local variable declaration or use is only as much cognitive load as represented by it being a line of code.
- A class level field is an order of magnitude more effort to reason about than a local, since it requires scanning to the definition and other uses.
- A global variable is an order of magnitude more effort to reason about than a class level field, since one has to leave the file to go find usages in other files.
It is worth noting here that neither experiment included class or globally scoped fields, though every method in the experiments did include a single parameter. (As an aside, it is also interesting, and probably problematic, that a method with zero lines of code would, apparently, require 6.6 seconds to comprehend). I do not think that we’re at an exact enough point to concern ourselves overmuch with double counting. Here is a rough cut of a new formula to try.
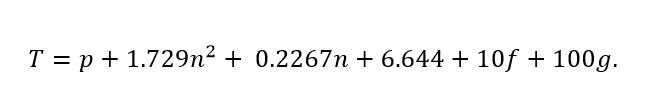
This is a formula where T is the time in seconds, p is the number of parameters, n the number of logical lines of code, f the number of class fields, and g the number of globals.
To see how this does as a predictor, I’m going to queue up one more experiment. In terms of rigor, it’s worth noting that I’m definitely varying more than one concern at a time here, so don’t look for this to be in a scientific journal, per se. Rather, my aim here is to wrap up the series by seeing how much progress we’ve made toward understanding time to comprehend. Stay tuned for the final post in the series, in which I’ll share the results.
Comments are closed.